About
We propose a novel deep learning framework that focuses on decomposing the motion or the flow of the pixels from the background for an improved and longer prediction of video sequences. We propose to generate multi-timestep pixel level prediction using a framework that is trained to learn the temporal and spatial dependencies encoded in video data separately. The proposed framework called Velocity Acceleration Network or VANet is capable of predicting long term video frames for the static scenario, where the camera is stationary, as well as the dynamic partially observable cases, where the camera is mounted on a moving platform (cars or robots). This framework decomposes the flow of the image sequences into velocity and acceleration maps and learns the temporal transformations using a convolutional LSTM network. Our detailed empirical study on three different datasets (BAIR, KTH and KITTI) shows that conditioning recurrent networks like LSTMs with higher order optical flow maps results in improved inference capabilities for videos.
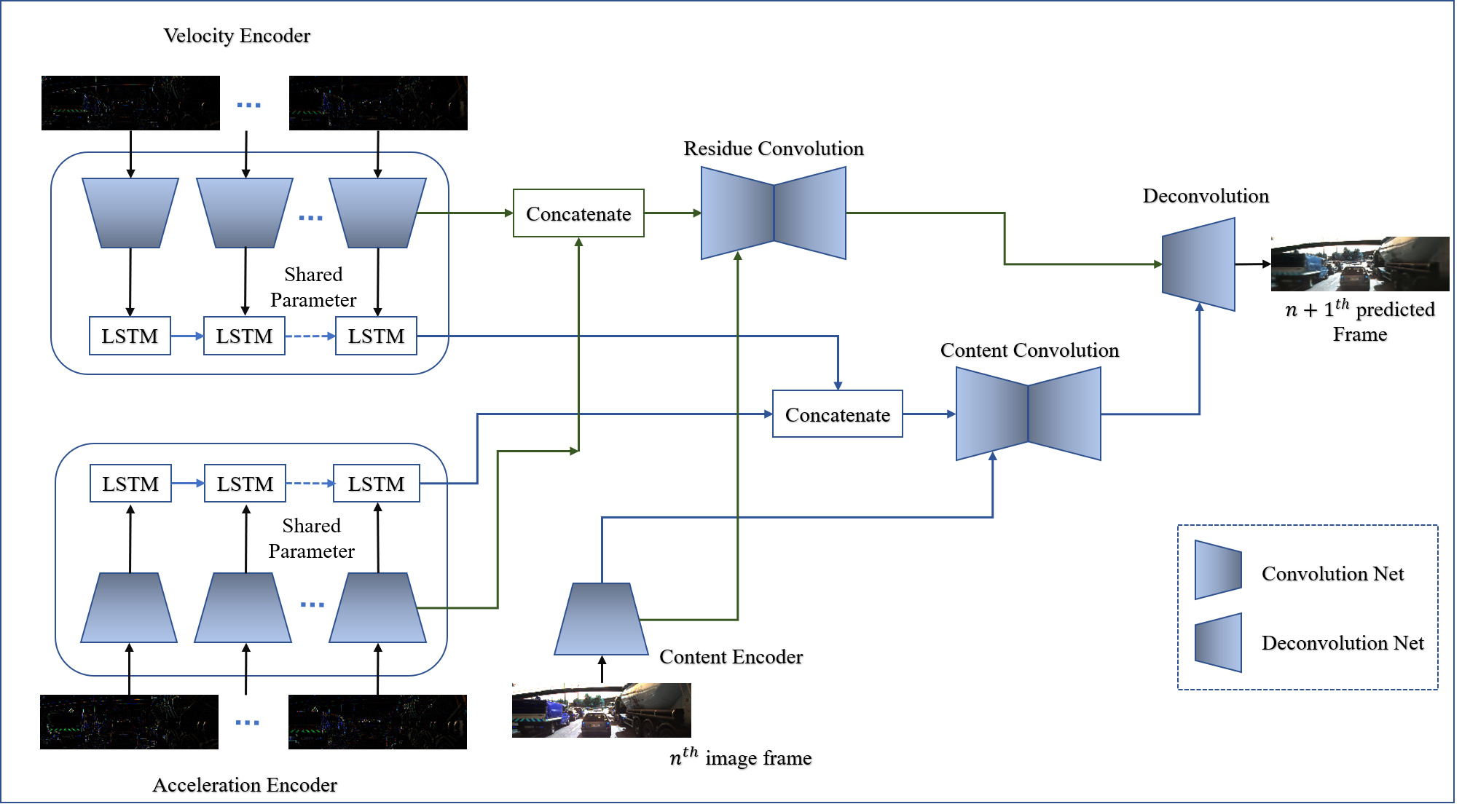
Architecture of VANet
BAIR Towel Pick Dataset



 Results from Ground Truth, VANet, MCNet and SVG respectively (from left to right)
Results from Ground Truth, VANet, MCNet and SVG respectively (from left to right)
KITTI Dataset



 Results from Ground Truth, VANet, MCNet and SVG respectively (from left to right)
Results from Ground Truth, VANet, MCNet and SVG respectively (from left to right)
Citation
If you are using VANet, please cite our paper as:
@InProceedings{pmlr-v148-sarkar21a,
title = {Decomposing camera and object motion for an improved video sequence prediction},
author = {Sarkar, Meenakshi and Ghose, Debasish and Bala, Aniruddha},
booktitle = {NeurIPS 2020 Workshop on Pre-registration in Machine Learning},
pages = {358--374},
year = {2021},
editor = {Bertinetto, Luca and Henriques, João F. and Albanie, Samuel and Paganini, Michela and Varol, Gül},
volume = {148},
series = {Proceedings of Machine Learning Research},
month = {11 Dec},
publisher = {PMLR}
}
##